There are a couple I have in mind. Like many techies, I am a huge fan of RSS for content distribution and XMPP for federated communication.
The really niche one I like is S-expressions as a data format and configuration in place of json, yaml, toml, etc.
I am a big fan of Plaintext formats, although I wish markdown had a few more features like tables.
The metric system, f*ck the imperial system. Every scientist sticks to the metric system, and why are people even still having an imperial system, with outdated measurements like stones for weight blows my mind.
Also f*ck Fahrenheit, we have Celsius and Kalvin for that, we don’t need another hard to convert temperature measurement.
Also f*ck Fahrenheit, we have Celsius and Kalvin for that,
Who is Kalvin? Did you mean kelvin?
One drawback of celsius/centigrade is that its degrees are so coarse that weather reports / ambient temperature readings end up either inaccurate or complicated by floating point numbers. I’m on board with using it, but I won’t pretend it’s strictly superior.
A degree Celsius is not coarse and does not require decimals in weather reports, and I suspect only a person who has never lived in a Celsius-using country could make such silly claims.
IRC.
Jabber.
IPFS.
I don’t use XMPP but it seems like such a no-brainer
Not matrix? XMPP is a good idea, but the wildly different levels of support among clients cause problems even back in its heyday Matrix solves some of that, fully encrypted, chat history stored on the server in encrypted form, supports gateways to other services.
Definitely not matrix.
Those problems you speak of about XMPP are not really a concern anymore and haven’t been for a while.
Matrix on the other hand is very difficult to implement, and currently there’s only one (maybe two?) viable implementation choices. It is way over complicated, resource intensive, and has privacy issues.
Does it have privacy issues compared to XMPP which doesn’t enforce the privacy extensions? I figure they are about the same there. Asking genuinely as I do not know other than Matrix might leak some metadata.
And quite frankly, I really wish we’d just agree on one or the other. Would love to host an instance and move some people to it but both are just stuck in this quasi-half used/half not state. And even people on here can’t agree what should be “standard.”
Xmpp definitely wins in privacy. What is there to privacy more than message content and metadata? Matrix definitely fails the second one, and is E2E still an issue for public groups? I don’t remember if they fixed that.
XMPP being a protocol built for extensibility means it will be hard for it not to keep up with times.
On your point of picking one or the other, I’d say pick the one you like and bridges will help you connect to the other. But XMPP came way before matrix, and I believe they fractured the community instead of building it.
There’s a good reason all the big techs built on top of xmpp (meta, Google, etc). It’s a very good protocol and satisfies modern demands very well.
Xmpp definitely wins in privacy. What is there to privacy more than message content and metadata? Matrix definitely fails the second one, and is E2E still an issue for public groups? I don’t remember if they fixed that.
XMPP being a protocol built for extensibility means it will be hard for it not to keep up with times.
Okay so how does modern XMPP protect this? When I last used XMPP, some (not all) clients supported OTR-IM, a protocol for end to end encryption. And there wasn’t a function for server stored chat history (either encrypted or plaintext).
Have these issues been fixed?It’s not perfect yet, but it’s much, much better than the old days.
OMEMO is supported by every major client, and they interoperate successfully. Unfortunately, most clients are stuck with an older version of the OMEMO spec. It’s not ideal, but it doesn’t cause any practical issue, unless you use Kaidan or UWPX, which only support the latest version.
All popular clients and servers support retrieving chat history now too.
In practice, I’ve been using it for several months to chat with friends and family, and haven’t had any issues.
It’s completely bonkers that JPEG-XL is as good as it is and no one wants to actually implement it into web browsers
Adobe is backing the format, Apple support is coming along, and there are rumors that Apple is switching from HEIC to JPEG XL as a capture format as early as the iPhone 16 coming out in a few weeks. As soon as we have a full blown workflow that can take images from camera to post processing to publishing in JXL, we might see a pretty strong push for adoption at the user side (browsers, websites, chat programs, social media apps and sites, etc.).
Do you know QOI format ? I would appreciate your opinion about it.
QOI is just a format that’s easy for a programmer to get their head around.
It’s not designed for everyday use and hardware optimization like jpeg-xl is.
You’re most likely to see QOI in homebrewed game engines.
What’s so good about it?
- Existing JPEG files (which are the vast, vast majority of images currently on the web and in people’s own libraries/catalogs) can be losslessly compressed even further with zero loss of quality. This alone means that there’s benefits to adoption, if nothing else for archival and serving old stuff.
- JPEG XL encoding and decoding is much, much faster than pretty much any other format.
- The format works for both lossy and lossless compression, depending on the use case and need. Photographs can be encoded in a lossy way much more efficiently than JPEG and things like screenshots can be losslessly encoded more efficiently than PNG.
- The format anticipates being useful for both screen and prints. Webp, HEIF, and AVIF are all optimized for screen resolutions, and fail at truly high resolution uses appropriate for prints. The JPEG XL format isn’t ready to replace camera RAW files, but there’s room in the spec to accommodate that use case, too.
It’s great and should be adopted everywhere, to replace every raster format from JPEG photographs to animated GIFs (or the more modern live photos format with full color depth in moving pictures) to PNGs to scanned TIFFs with zero compression/loss.
Existing JPEG files (which are the vast, vast majority of images currently on the web and in people’s own libraries/catalogs) can be losslessly compressed even further with zero loss of quality. This alone means that there’s benefits to adoption, if nothing else for archival and serving old stuff.
Funny thing is, there was talk on the Chrome bug tracker of using just this ability transparently at the HTTP layer (like gzip/brotli compression), but they’re so set on pushing their AVIF format that they backed away from it.
- The format works for both lossy and lossless compression, depending on the use case and need. Photographs can be encoded in a lossy way much more efficiently than JPEG and things like screenshots can be losslessly encoded more efficiently than PNG.
Someone made a fair point that having a format being both lossy and lossless is not necessarily a great idea. If you download a jpeg file you know it will be compressed, if you download png it will be lossless. Shifting through jxl files to check if it’s lossy or not doesn’t sound very fun.
All in all I’m a big supporter of jxl though, it’s one of the only github repos I actively follow.
Functionally speaking, I don’t see this as a significant issue.
JPEG quality settings can run a pretty wide gamut, and obviously wouldn’t be immediately apparent without viewing the file and analyzing the metadata. But if we’re looking at metadata, JPEG XL reports that stuff, too.
Of course, the metadata might only report the most recent conversion, but that’s still a problem with all image formats, where conversion between GIF/PNG/JPG, or even edits to JPGs, would likely create lots of artifacts even if the last step happens to be lossless.
You’re right that we should ensure that the metadata does accurately describe whether an image has ever been encoded in a lossy manner, though. It’s especially important for things like medical scans where every pixel matters, and needs to be trusted as coming from the sensor rather than an artifact of the encoding process, to eliminate some types of error. That’s why I’m hopeful that a full JXL based workflow for those images will preserve the details when necessary, and give fewer opportunities for that type of silent/unknown loss of data to occur.
IPv6. Stop engineering IoT junk on single-stack IPv4, you dipshits.
Ogg Opus. It’s superior to everything in every way. It’s free and there is absolutely no reason to not support it. It blows my mind that MPEG 1.0 Layer III is still so dominant.
ISO 8601 date format. Not because it’s from a standards body, but because it’s simple, sensible, clearly defined, easy to recognize, and very effective.
Date field placement in any order other than most-significant-digits-first is not only counterintuitive, but needlessly complicated to work with. Omitting critical information like the century is ambiguous and confusing.
We don’t live in isolated villages any more. Mixing and matching those problems by accepting all the world’s various regional and personal date styles, especially with no reliable indication of which ones apply in any given case, leads to the hodgepodge of error-prone date madness that we have today.
The 2024-09-02 format should be taught in schools and required in official documents. Let the antiquated date styles fall into disuse outside of art and personal correspondence, like cursive writing.
I’ll give my usual contribution to RSS feed discourse, which is that, news flash! RSS feeds support video!
It drives me crazy when podcasters are like, “thanks for listening to our audio podcasts. We also have a video feed for our YouTube subscribers.” Just let me have the video in PocketCasts please!
I just wrote a YouTube scraper and exported to RSS and into my podcast client. Using YouTube any other way is masochism in comparison.
TOML instead of YAML or JSON for configuration.
YAML is complex and has security concerns most people are not aware of.
JSON works, but the block quoting and indenting is a lot of noise for a simple category key value format.
YAML is complex and has security concerns most people are not aware of.
YAML is racist to Norwegians.
If you have something like
country: NO(NO = Norway), YAML will turn that intocountry: False. Why? Implicit casting. There are a bunch of truthy strings that’ll be cast automagically.
Zigbee or really any Bluetooth alternative.
Bluetooth is a poorly engineered protocol. It jumps around the spectrum while transmitting, which makes it difficult and power intensive for bluetooth receivers to track.
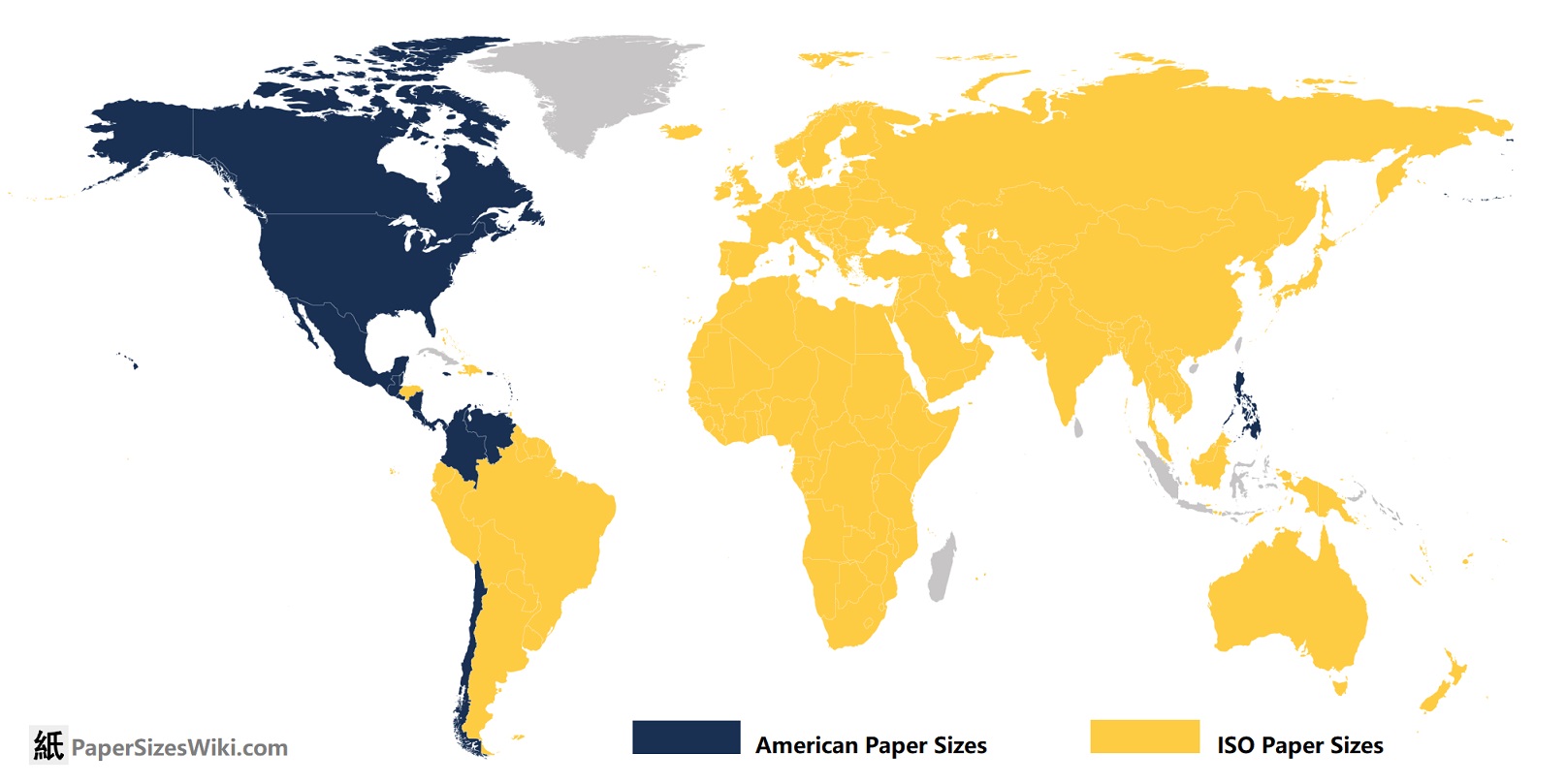
ISO 216 paper sizes work like this: https://www.printed.com/blog/paper-size-guide/
It’s so fucking neat and intuitive! How is it not used more???
sorry to tell you this bud…
deleted by creator
What resource did you use to master it? As every time I have to use regex I want to cry.
deleted by creator